Python 爬蟲筆記
本篇記錄用 Python 實做爬蟲的一些筆記。
用 Docker 跑 Selenium 模擬瀏覽器
用 Docker-compose 啟動模擬的 Chrome
由於不想做成讓 Python 直接操作本機的瀏覽器,這裡選擇尋找適合的 Docker image 來實現這件事。剛好 Selenium 有做這件事,他們將 Linux 加不同的瀏覽器包成 Containers,可以選擇 Firefox, Chrome 和 Microsoft Edge。詳情可參考 SeleniumHQ/docker-selenium。
裡面寫的 README 有指令可以啟動 Docker container,但我個人偏好使用 docker-compose,這樣只要檔案寫好,簡單的指令就可以啟動了。以下為 docker-compose + Chrome 的 yml 檔。
version: '3'
services:
chromedrive:
image: selenium/standalone-chrome-debug
ports:
- 4444:4444
- 5900:5900
environment:
- VNC_NO_PASSWORD=1在 terminal 打上 docker-compose up 即可。其中
- port 4444 就是 WebDriver 的位置,屆時程式碼會指向這個 port
- 5900 則是 VNC Server 的 port,因為是 Docker 中 Chrome,本機是看不到的,就必須透過 VNC 來看
- environment 中的
VNC_NO_PASSWORD=1則是把指定不需輸入 VNC 密碼也能直接使用
用 Python 在 Jupyter notebook 控制瀏覽器
啟動了 Selenium 控制 Chrome WebDriver 後,就可以正式開始寫程式抓資料了。這裡選擇使用 Juyputer Notebook,因為可以更方便的 Debug 並看到即時的結果。
在 Terminal 中開啟 Jupyter Notebook:jupyter notebook。
首先要先安裝 selenium 的 Python 套件,在 Jupyter Notebook 中可以直接加上 ! 來安裝
!pip3 install selenium再來引入 Selenium 相關的 modules
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities然後控制我們剛剛用 Docker-compose 啟動的 Container
driver = webdriver.Remote(command_executor='http://localhost:4444/wd/hub', desired_capabilities=DesiredCapabilities.CHROME)輸入正確 WebDriver 的 Server 位置及 port,由於 docker 和本機 bonding port 4444,故輸入如上。再來測試一下取得某個頁面的內容,就抓取「霍爾筆記」的首頁試試
driver.get('https://www.howardsnotes.tw/')沒有發生錯誤的話,應該就是取得成功了!但什麼都沒顯示,要如何才知道成功抓取了呢?我們可以用用看 xpath 來取得頁面的某段文字,例如「霍爾筆記」的標題,我們找出其 xpath 是什麼。
首先到頁面,如果你是用 Chrome 的話,可以開啟開發者模式,並在標題的 DOM 上面按右鍵「複製 xpath」

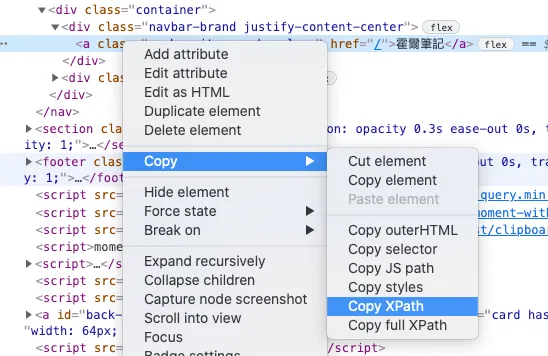
你就會得到一段 /html/body/nav/div/div[1]/a 這樣的文字,透過 Selenium,就可以定位到這個 DOM component 了
result = driver.find_elements_by_xpath('/html/body/nav/div/div[1]/a')
print(result[0].text)用 find_elements_by_xpath 會得到一個 array,由於我們定位的 component 只有一個,第 0 個元素就是我們要取得的 component,裡面的文字可透過 .text 來獲取,最後得到結果「霍爾筆記」。
透過 VNC 觀察瀏覽器狀況
在執行爬蟲任務時,如果光打程式碼看結果,發生錯誤時可能很難知道是為何,有可能是網站本身連線就有問題,或是我們的 code 哪裡打錯了。
這時如果可以看到瀏覽器的畫面,情況就會明瞭的多!由於我們使用 Docker,並非直接控制本機的 Chrome,就需要透過 VNC 遠端控制 Docker 中的 OS。
此時打開 VNC Viewer,或類似的遠端控制軟體,輸入位置為 localhost:5900,port 也就是我們剛剛在 docker-compose.yml 裡連結的。就可以看到一個跑著 Linux 瀏覽器了
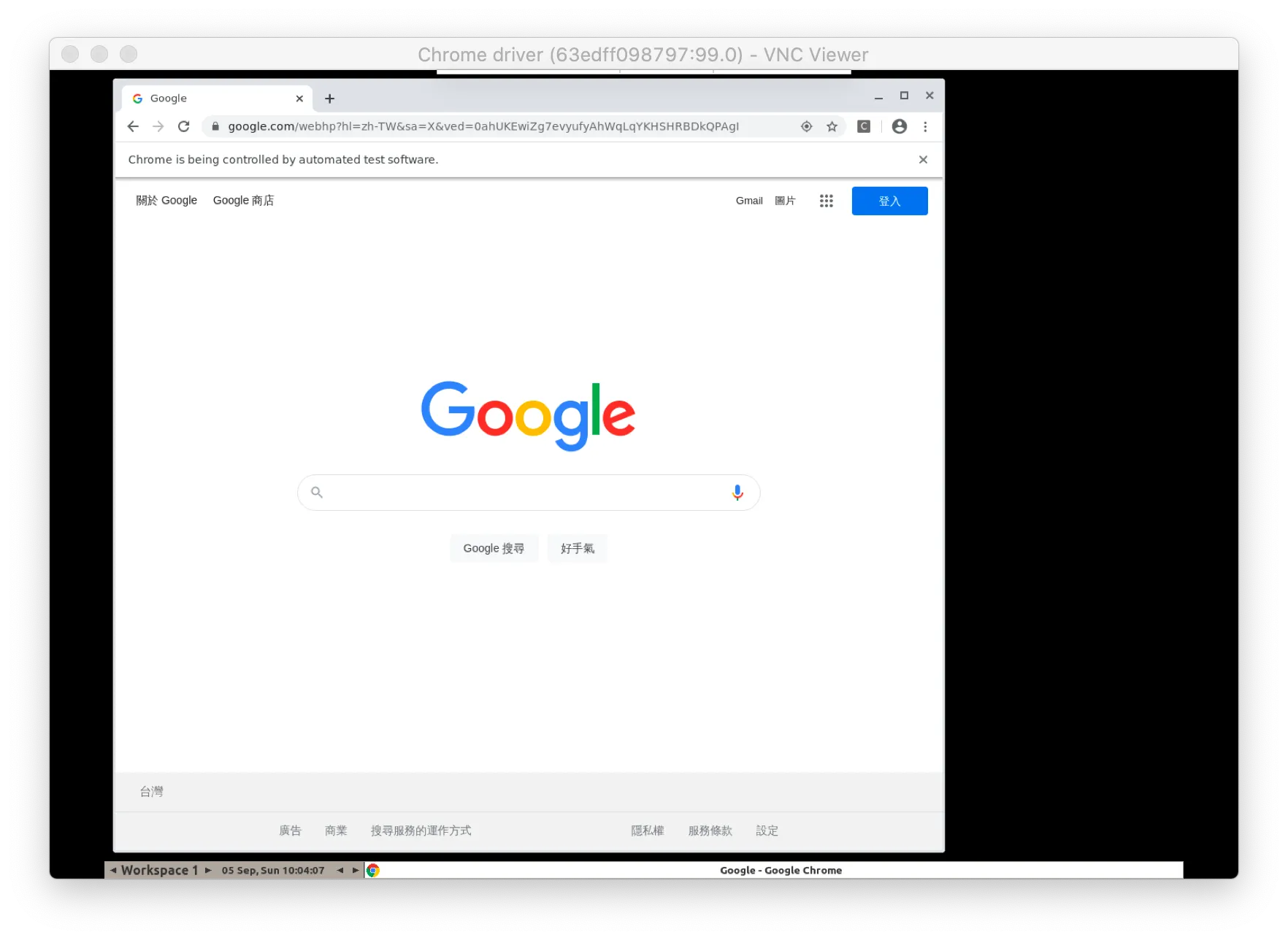
也可以用直接操控整個 OS,像是在瀏覽器隨意點擊等等,都更方便的讓我們開發爬蟲。
控制 UI 的指令
除了取得某個網頁裡的內容外,要做爬蟲當然得和頁面互動才行,例如輸入文字、點擊等等。假設我們要取得 Google 搜尋的某個結果,我們要做的就是
- 進入到 Google 搜尋頁面
- 輸入要搜尋的文字(首先要先定位搜尋框)
- 點擊「搜尋」(或是按 Enter)
- 抓取裡面的內容
以下就是做這些事的程式碼
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.keys import Keys
driver = webdriver.Remote(command_executor='http://localhost:4444/wd/hub', desired_capabilities=DesiredCapabilities.CHROME)
driver.get('https://www.google.com/')
driver.find_elements_by_xpath('/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')[0].send_keys('dog')
driver.find_elements_by_xpath('/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')[0].send_keys(Keys.ENTER)
driver.find_elements_by_xpath('//*[@id="rso"]/div[3]/div/div/div[1]/a/h3')[0].text第 7 和第 8 行是用上面的技巧,找到搜尋框的位置,並用 send_keys 這個 function 輸入我們要搜尋的內容,然後按下 Enter(這裡用到第三行的 import),
再來第 9 行則是取得第一筆搜尋結果,也是直接在網頁裡找 xpath 的成果,接著我們發現只要把 xpath //*[@id="rso"]/div[?] 裡面的 ? 改成 4, 5, … 就可以拿到接下來的搜尋結果了!
雖然 Google 的搜尋結果會因為使用者的地區、登入資訊等等有所不同,但這邊示範的內容是可以應用在其它網站的,爬蟲就是展現所有可能的方式,盡可能取得網頁的資訊,並想辦法去定位。